
Energy efficient path planning method for coal mine patrol robot
-
摘要:
针对现有矿用机器人路径路规划方法存在的效率低、收敛速度慢、易陷入局部最优等不足,提出了一种基于Actor-Critic算法的路径规划方法。首先根据巡检目标和障碍物的实时位置信息,计算巡检机器人的转向角,确定行进方向,可显著提高路径规划的效率;以能量消耗最小化和避免碰撞为目标,巡检机器人根据动态随机变化的矿山环境,学习巡检的目标顺序和行进速度;因为矿山环境动态连续变化,导致较高的状态维度,因此采用深度学习网络估计连续状态产生的动作和奖赏;为了提高学习效率,采用策略网络和价值网络2个网络,实现实时更新策略和价值。仿真结果表明:采用所提方法,巡检机器人可以在动态环境中规划出安全合理的巡检路线,能够以98%的成功概率和更低的能量消耗完成巡检作业。
Abstract:In order to solve the shortcomings of the existing mining robot path planning methods, such as low efficiency, slow convergence speed, and easy to fall into local optimum, a path planning method based on Actor-Critic algorithm is proposed. Firstly, according to the real-time position information of the inspection target and the obstacles, the steering angle of the patrol robot is calculated and the forward direction is determined, which can significantly improve the efficiency of path planning. With the goal of minimizing energy consumption and avoiding collisions, the patrol robot learns the target inspection sequence and forward speed according to the dynamically changing mining environment. Because the dynamic and continuous changes of the mine environment lead to a high state dimension, the action and reward generated by the continuous state are estimated by the deep learning networks. In order to improve the efficiency of learning, two networks are adopted, namely the Actor network and the Critic network, to achieve real-time update of strategy and value. The simulation results show that the proposed method can design a safe and reasonable patrol route in a dynamic environment, and can complete the patrol task with a 98% success probability and lower energy consumption.
-
矿山环境复杂、空间狭小、视觉环境差,并且存在部分易燃、易爆、易腐蚀等危险品,存在人工危险性大、巡检精确度不稳定和巡检效率低等问题。随着煤炭行业的智能化水平逐渐提高,巡检机器人采用耐腐蚀表面材料,可以在高温恶劣环境中保持良好工作状态,完成漏液检测、温度检测、有毒气体检测等巡检工作[1]。在巡检工作中,巡检机器人采集实时数据,将数据发送到智能运维平台,发现异常数据后发送警报信号。同时,巡检机器人还可以对数据先进行预处理,方便工作人员做出更科学的决策。
在巡检工作中,合理安全的路径规划对机器人至关重要。然而,由于工作人员走动、其他智能设备移动等,矿山环境动态随机变化,对巡检机器人的路径规划和动态避障提出了挑战。目前,移动机器人的传统路径规划方法有人工势场方法[2-3]、快速探索随机树算法[4](Rapidly-exploring Random Trees,RRT)和A*算法[5-6]等。然而,人工势场方法缺乏全局地图信息,不适用于全局路径规划;RRT算法需要庞大的搜索空间,路径规划的效率不高;A*算法在静态全局规划中很有效,但是不适用于动态随机的矿山环境。为了解决动态路径规划问题,有学者提出基于蚁群算法[7-8]、遗传算法[9]、粒子群算法[10]等启发式算法的路径规划方法。启发式算法可以根据部分信息进行自学习,但是容易陷入局部最优,而且收敛速度较慢。强化学习可以实时与环境交互,根据环境变化调整路径,已被广泛应用于机器人路径规划。文献[11]为了克服维度诅咒和降低历史数据关联性,避免陷入局部最优解,提出了一种重放回机制DQN(Deep Q-Network,深度Q网络)算法。但是使用一个策略采集完整轨迹的方差较大,学习效率较低。因此,提出一种结合策略梯度和时序差分学习的强化学习路径规划方法。
巡检机器人的能量非常重要,可以保障更长时间的工作。为了提高路径规划效率和提高机器人的工作时间,采用面向目标的转向角控制方法,并利用Actor-Critic算法选择巡检速度,根据动态随机的移动障碍物,以能量消耗最小化为目标规划巡检路线,实现机器人的无碰撞自主导航,在确保路线安全、合理的基础上,进一步降低巡检机器人的能量消耗。
1. 研究方法
矿山环境复杂多变,导致复杂多样的连续状态,传统离散化状态的方法不可取。为了在连续状态下产生合理高效的巡检路径,采用Actor-Critic深度强化学习算法。Actor-Critic算法包括策略网络和价值网络,可以进行单步更新,学习效率高。同时,为了解决传统深度Q-learning算法的过估计问题,考虑双策略网络和双价值网络,分别称为目标策略网络和目标价值网络,结构分别与策略网络和价值网络相同。
价值网络的Q值用$ Q\left( {s,a\left| {{w}} \right.} \right) $近似,策略网络的参数化策略用$ v\left( {s,a\left| {{\theta }} \right.} \right) $近似,其中:w、θ分别为表示价值网络和策略网络的参数,分别构成相应神经网络中激活函数的连接权值和偏差。为了减小样本之间的相关性,采用经验池存放历史样本。在每次训练中,从经验池中随机选择小批量的样本$ {\varPhi _{\mathrm{b}}} $更新策略网络的参数$ {{\theta }} $,更新公式为:
$$ {{\theta }} \leftarrow {{\theta }} + \frac{\alpha }{{\left| {{\varPhi _{\mathrm{b}}}} \right|}}{\nabla _{{\theta }}}v\left( {s,a\left| {{\theta }} \right.} \right){\nabla _{a'}}Q\left( {s,a'\left| {{w}} \right.} \right)\left| {_{a' = v\left( {s,a\left| {{\theta }} \right.} \right)}} \right. $$ (1) 式中:$ \alpha $为学习率;$ s $为矿山巡检环境的状态;$ a $为巡检机器人采取的动作;$ a' $为下一时隙机器人采取的动作。
价值网络的参数更新表达式为:
$$ {{w}} \leftarrow {{w}} - \frac{\alpha }{{\left| {{\varPhi _{\mathrm{b}}}} \right|}}{\sum\limits_{{\varPhi _{\mathrm{b}}}} {{\nabla _{{w}}}\left( {\xi - Q\left( {s,a\left| {{w}} \right.} \right)} \right)} ^2} $$ (2) 式中:$ \xi = R_{ss'}^a + C_{ss'}^a + \gamma Q\left( {s,v\left( {s,a\left| {{{\theta }}'} \right.} \right)\left| {{{w}}'} \right.} \right) $;$ R_{ss'}^a $为在状态$ s $采取动作$ a $后转移到状态$ s' $的奖赏;$ C_{ss'}^a $为在状态$ s $采取动作$ a $后转移到状态$ s' $的惩罚;$ \gamma $为奖赏折扣因子。
目标策略网络参数$ {{\theta }}' $和目标价值网络参数$ {{w}}' $更新公式为:
$$ {{w}}' \leftarrow \eta {{w}} + \left( {1 - \eta } \right){{w}}' $$ (3) $$ {{\theta }}' \leftarrow \eta {{\theta }} + \left( {1 - \eta } \right){{\theta }}' $$ (4) 式中:$ \eta $为远小于1的正值,保证算法稳定收敛。
2. 路径规划方法
2.1 巡检机器人坐标优化问题转化
在煤矿作业场景中,巡检机器人的巡检区域较大,直接应用强化学习优化巡检机器人的下一时隙坐标时,动作空间很大,导致学习效率比较低,路径规划的精度和效率难以权衡。当已知巡检机器人当前时隙坐标$ {{q}}\left( t \right) $和行进方向$ \varphi \left( t \right) $,以及下一时隙的转向角$ \Delta \left( {t + 1} \right) $和速度$ v\left( {t + 1} \right) $确定时,巡检机器人的行进方向和坐标可以更新为:
$$ \varphi \left( {t + 1} \right) = \varphi \left( t \right) + \Delta \left( {t + 1} \right) $$ (5) $$\begin{split} &\begin{gathered} {{q}}\left( {t + 1} \right) = \left( {x\left( t \right) + v\left( {t + 1} \right)\tau \cos\; \varphi \left( {t + 1} \right),} \right. \\ {\text{ }}\left. {y\left( t \right) + v\left( {t + 1} \right)\tau \sin\; \varphi \left( {t + 1} \right)} \right) \end{gathered}\\[-16pt]& \end{split}$$ (6) 式中:$ x\left( t \right) $为时隙$ t $巡检机器人的横坐标;$ y\left( t \right) $为时隙$ t $巡检机器人的纵坐标;$ \tau $为单个时隙的时长。
因此,巡检机器人的路径规划问题可看作马尔科夫过程,利用强化学习求解。首先根据巡检机器人的定位信息和巡检目标的位置信息,在机器人最大转向角约束和碰撞避免约束下计算巡检机器人每时隙的转向角,调整行进方向,然后利用Actor -Critic算法优化巡检机器人的速度。当机器人转向角和速度确定时,可以进一步计算巡检机器人各个时隙的坐标,进而得到巡检路线。
2.2 面向目标的转向角控制方法
巡检机器人配置感知模块和定位模块,可以感知周围环境信息和确定位置信息。当巡检机器人未感知到障碍物时,其决策模块根据自身坐标和巡检目标坐标计算转向角$\Delta \left( t \right) $为:
$$ \Delta \left( t \right) = \left\{ \begin{gathered} \min \left( {{\varphi _{\mathrm{r}}}\left( t \right) - \varphi \left( t \right),{\varphi _{\max }}} \right),{\varphi _{\mathrm{r}}}\left( t \right) \geqslant \varphi \left( t \right) \\ \max \left( {{\varphi _{\mathrm{r}}}\left( t \right) - \varphi \left( t \right), - {\varphi _{\max }}} \right),\qquad\;{\text{else}} \\ \end{gathered} \right. $$ (7) 式中:$ {\varphi _{\mathrm{r}}}\left( t \right) $为时隙$ t $时巡检机器人与巡检目标相对于$ x $正半轴的角度;$ {\varphi _{\max }} $为巡检机器人的最大转向角。
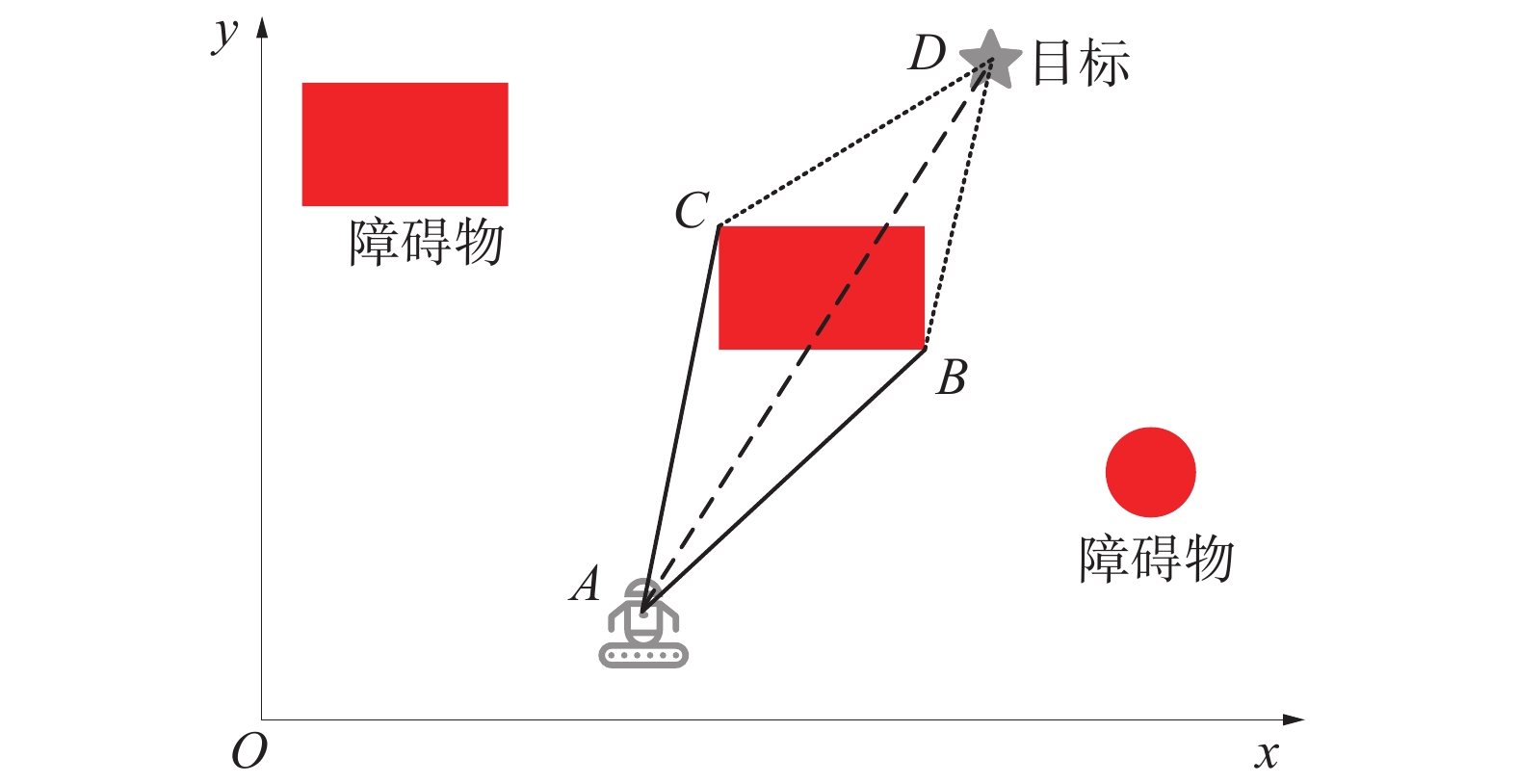
面向目标的避障转向角控制方法示意图如图1所示。
![]() 图 1 面向目标的避障转向角控制方法示意图Figure 1. Diagram of target oriented obstacle avoidance steering angle control method
图 1 面向目标的避障转向角控制方法示意图Figure 1. Diagram of target oriented obstacle avoidance steering angle control method当巡检机器人感知到障碍物时,巡检机器人在障碍物边界上以最大感知角度和感知距离探测障碍物的边界点,并分别计算障碍物边界点B和C、巡检机器人A和巡检目标D的相对角度。根据正弦定理,选择相对角度最小的障碍物边界点作为行进目标,使行驶路径更短,从而最小化能量消耗。然后,巡检机器人根据其当前坐标和行进目标的坐标计算下一时隙的转向角。同时,根据Actor-Critic算法输出的速度行驶。在每时隙,巡检机器人感知更新障碍物的边界点,直至与障碍物之间的距离大于安全距离。
采用面向目标的转向角控制方法,巡检机器人将在避开障碍物的同时向巡检目标行进,从而大大提高轨迹规划的效率。
2.3 路径规划方法
在各个时隙初始确定巡检机器人的转向角后,采用Actor-Critic算法优化巡检机器人的速度。考虑速度约束、避障约束和巡检时间约束,巡检机器人的路径规划问题是带约束的马尔科夫决策过程,用元组$ \left\langle {S,A,R,C,T} \right\rangle $定义,其中:$ S $为状态集;$ A $为动作空间;$ R $、$ C $分别为即时奖赏和惩罚;$ T $为状态转移函数。
各个参数定义为:
1)状态。包括机器人的行进方向和坐标、机器人与障碍物的距离、机器人与基地的距离。
2)动作。机器人的速度。
3)奖赏。设置为机器人的能量消耗。
4)惩罚。当机器人与障碍物的距离小于安全距离,机器人与基地的距离大于剩余时间所能行驶的最大距离,给予1个很大的惩罚。
5)转移函数。机器人在状态$ s $执行动作$ a $后转移到状态$ s' $的概率。在本文,状态转移函数是未知的,所以采用Actor -Critic算法训练机器人。
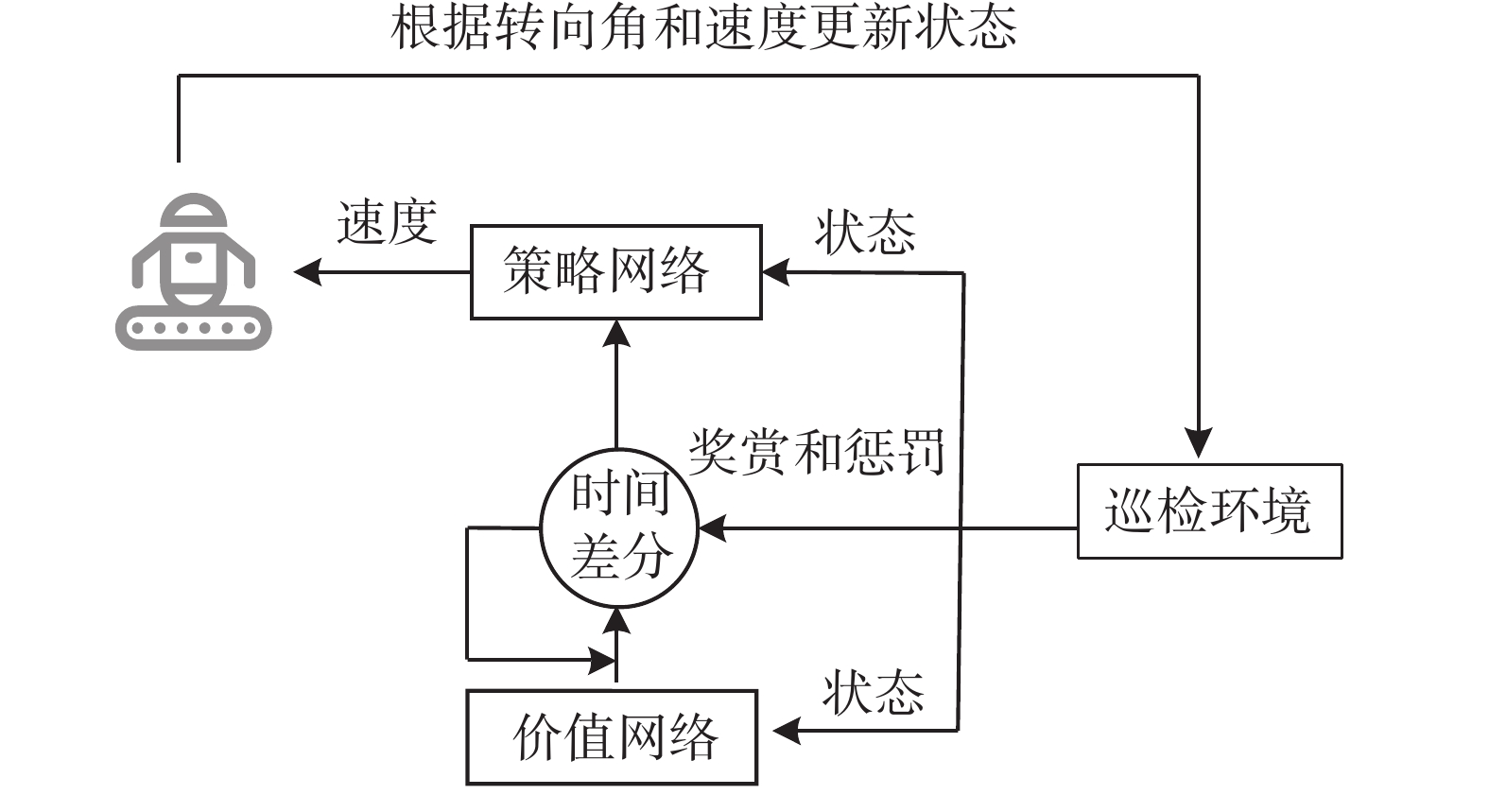
基于转向角控制方法和Actor -Critic算法的路径规划训练框架如图2所示。
![]() 图 2 基于Actor-Critic算法的路径规划训练框架Figure 2. Path planning training framework based on Actor-Critic algorithm
图 2 基于Actor-Critic算法的路径规划训练框架Figure 2. Path planning training framework based on Actor-Critic algorithm巡检机器人首先根据矿山巡检环境的状态$ s $,采用$ \varepsilon $贪婪算法选择动作$ a $。巡检机器人根据转向角调整行进方向并且执行动作$ a $,矿山巡检环境反馈奖赏和惩罚并转移到下一状态$ s' $。然后,将$ \left( {s,a,R,C,s'} \right) $作为1个样本存储在经验池中。每次训练时,从经验池中随机抽取部分样本更新策略网络的参数。另外,每隔$ \mu $个训练步骤,更新目标策略网络和目标价值网络的参数。
当算法收敛时,策略网络输出最优动作,使累积奖赏最小化,此时获得速度优化选择策略。根据不同的巡检环境,巡检机器人采用速度优化策略选择最优的速度,具有很好的迁移性。
3. 系统性能分析
为了验证基于Actor-Critic算法的巡检机器人路径规划方法的可行性和合理性,在Intel Xeon Gold 6226R CPU、256 RAM和NVIDIA Tesla P100-PCIE-16 GB GPU系统上使用Pytorch进行仿真实验。仿真中考虑1个长度为20 km、宽度为10 km的长方形巡检区域,区域中存在5个巡检目标、1个静态障碍物和1个动态障碍物。巡检机器人的最大转向角为20o,最大速度为20 m/s。巡检机器人从基地出发,要求在1 000个时隙内完成巡检,避免与其他障碍物发生碰撞,并返回基地。
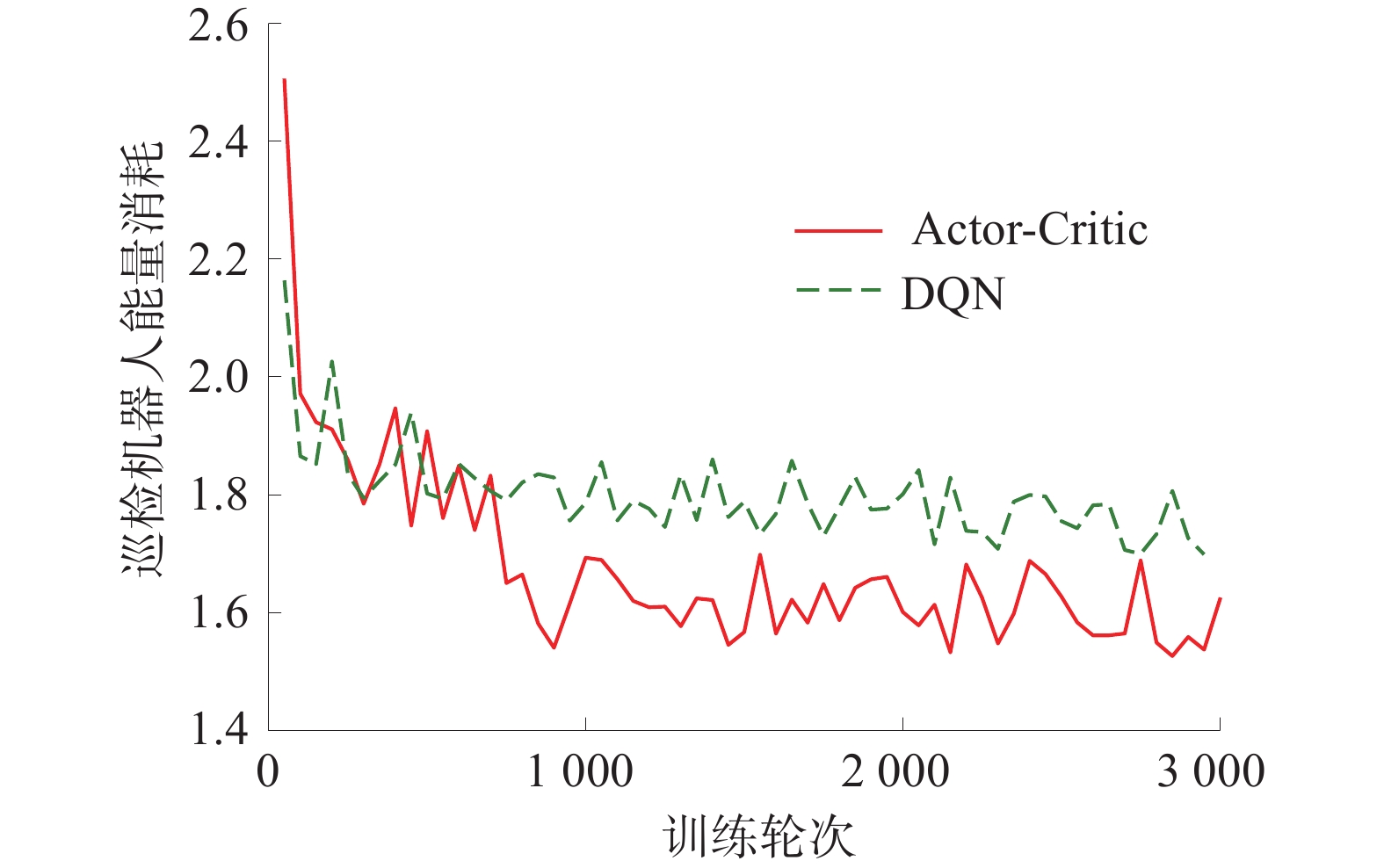
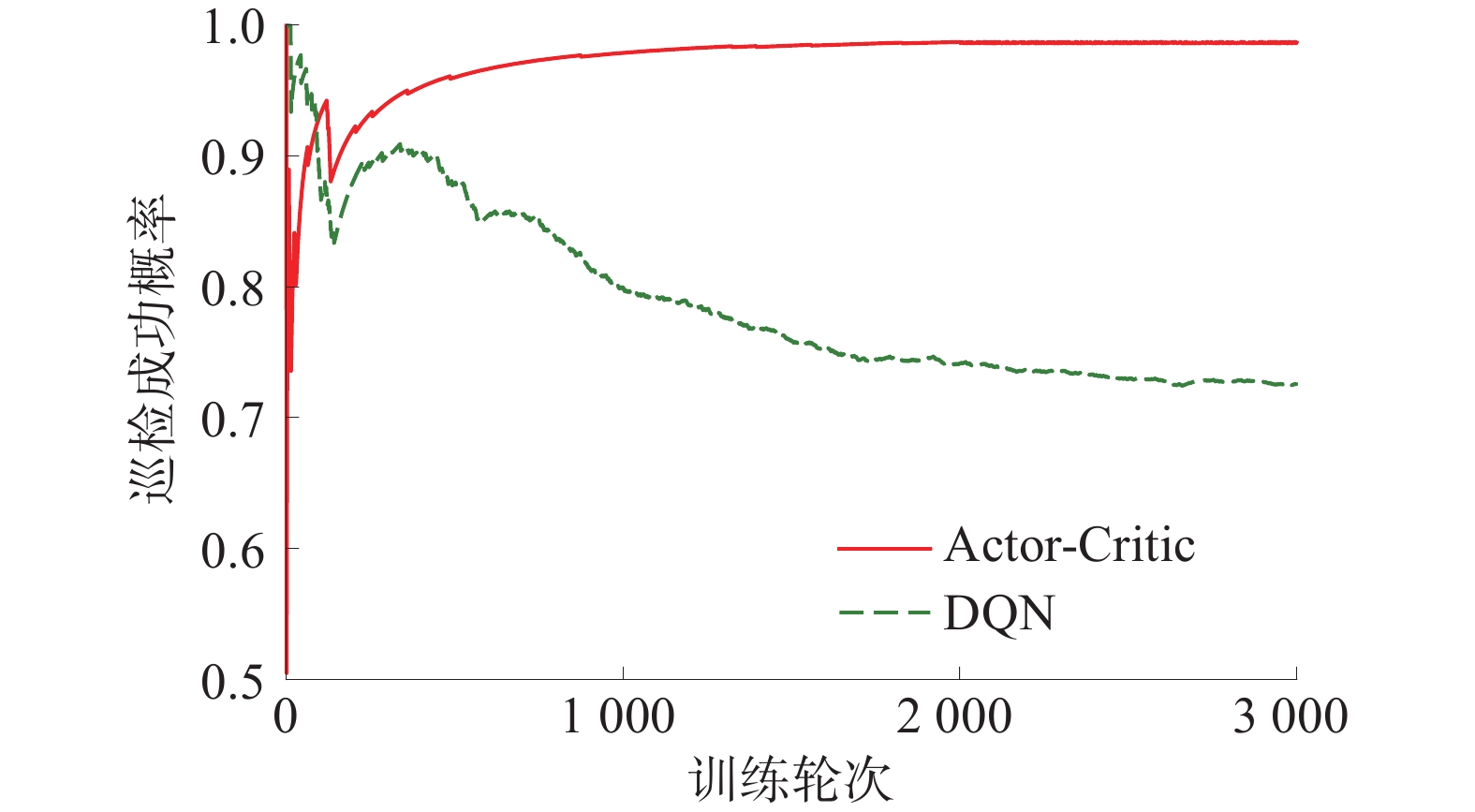
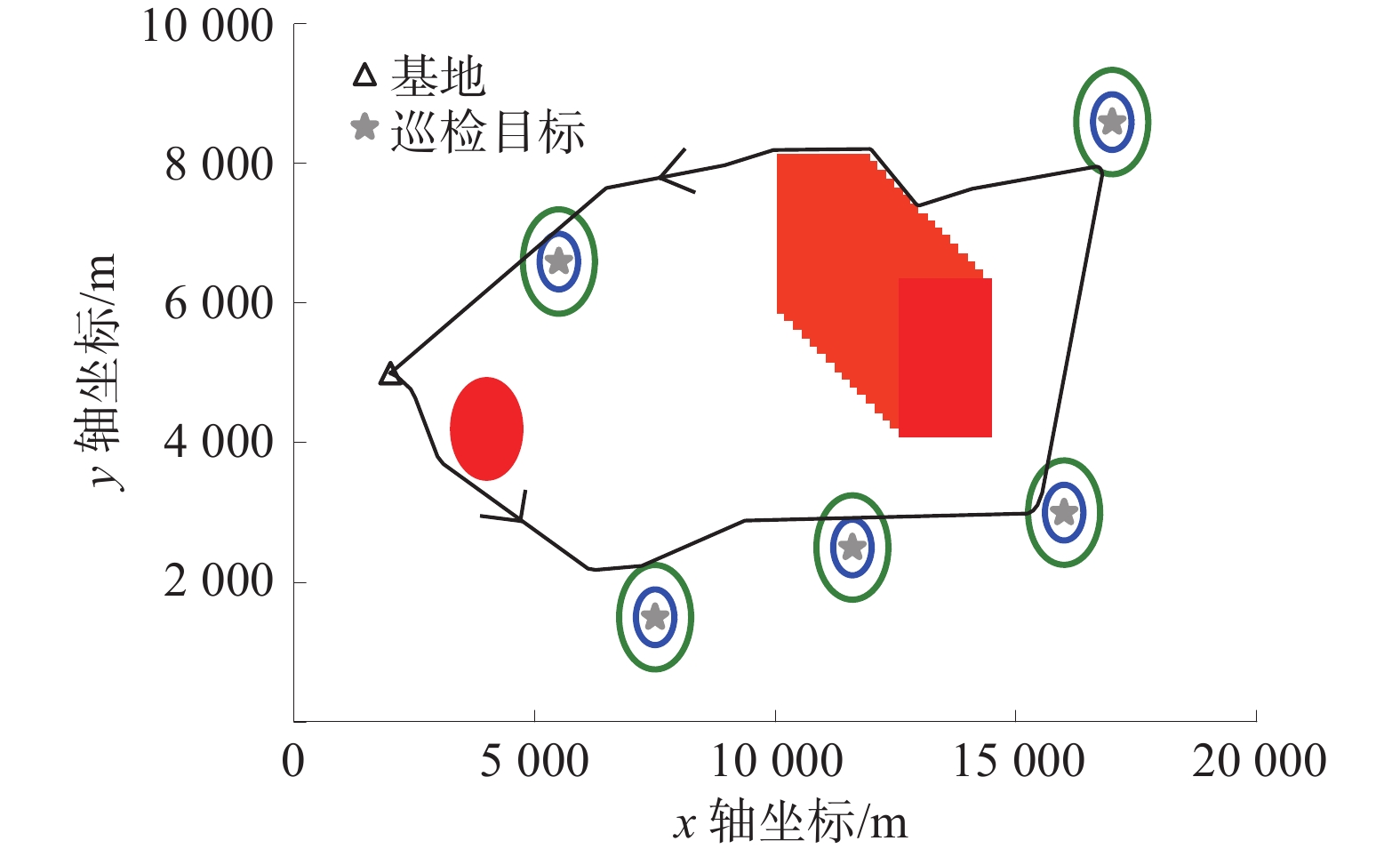
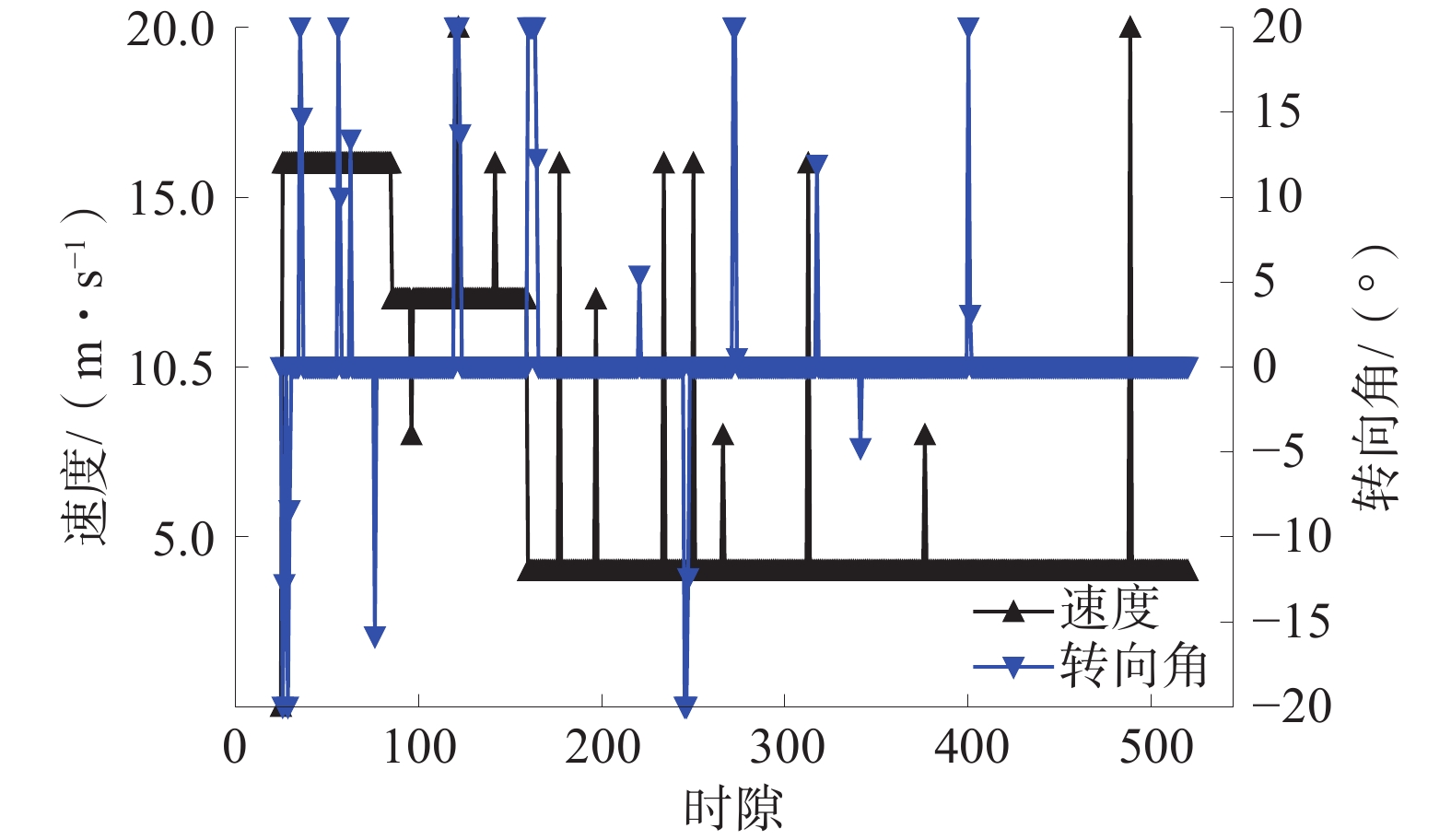
在相同环境和参数条件下,巡检机器人的转向角选择都采用面向目标的转向角控制方法,各个时隙的速度分别利用Actor-Critic算法和DQN算法训练,完成轨迹规划。所提路径规划方法的收敛性如图3所示,所提路径规划方法的成功概率如图4所示,巡检机器人路径规划结果如图5所示,巡检机器人的速度和转向角如图6所示。
由图3可知,基于Actor-Critic算法和DQN算法的路径规划都可以收敛,由于巡检机器人在每个状态下都存在一定的概率选择1个随机动作进行探索,所以2种算法的能量消耗值是波动的。由于DQN算法容易陷入局部最优,因此DQN算法的能量消耗高于Actor-Critic算法。
对于每1个训练轮次中,如果巡检机器人能够在规定时间完成所有煤矿设备的检查,并且不发生碰撞地返回基地,则此轮次巡检成功。某一轮次的成功概率表示为当前成功总轮次数与当前总轮次数的比值。由图4可以看出:Actor-Critic算法的巡检成功概率可以达到98%。与DQN算法相比,Actor-Critic算法具有更高的成功概率,因为DQN算法采用1个深度学习网络,巡检机器人易陷入局部最优速度,无法在规定时间完成巡检作业,导致较低的成功概率和较高的能量消耗。因此,所提方法的路径寻优效率更高,能够更好地满足煤矿巡检作业要求。
图5中:红色圆表示静态障碍物,红色长方形表示动态障碍物,绿色圆表示可检测距离,蓝色圆表示安全距离。由图5可以看出:巡检机器人从基地出发,以巡检目标为行进方向,在探测到障碍物后改变转向角;巡检机器人可以在避开障碍物的同时向巡检目标行驶,完成所有目标设备的巡检作业,并返回基地。
由图6可以看出:机器人在600时隙内完成巡检作业,小于所要求的1 000个时隙;另外,机器人会尽量采用恒定的速度行驶,以减小能量消耗。所提路径规划方法不仅可以提高深度学习算法的学习效率,而且可以以更短的路径完成巡检作业,节省能量消耗。
4. 结 语
1)针对巡检任务区域大,路径规划精度和效率难以权衡的问题,提出了1种面向巡检目标和基于Actor-Critic算法的巡检机器人路径规划方法。该方法以巡检目标为行进方向,根据环境位置信息计算机器人的转向角,可以加快路径规划过程。Actor-Critic算法可以解决单深度学习网络的低估问题,设计安全可行的巡检路线,降低巡检机器人的能量消耗。
2)仿真结果表明,提出的路径规划算法能够实现合理可行的巡检路径规划,并且具有较高的作业成功概率和较低的巡检能量消耗,可以大幅提高煤矿巡检工作的效率。此训练模型可以很方便地迁移到不同的作业环境。
-
![]()
图 1 面向目标的避障转向角控制方法示意图
Figure 1. Diagram of target oriented obstacle avoidance steering angle control method
![]()
图 2 基于Actor-Critic算法的路径规划训练框架
Figure 2. Path planning training framework based on Actor-Critic algorithm
-
[1] 葛世荣,胡而已,李允旺. 煤矿机器人技术新进展及新方向[J]. 煤炭学报,2023,48(1):54−73. GE Shirong, HU Eryi, LI Yunwang. New progress and direction of robot technology in coal mine[J]. Journal of China Coal Society, 2023, 48(1): 54−73.
[2] 谢春丽,陶天艺,李佳浩. 基于改进人工势场法的路径规划研究[J]. 吉林大学学报(信息科学版),2023,41(6):998−1006. XIE Chunli, TAO Tianyi, LI Jiahao. Research on path planning based on improved artificial potential field method[J]. Journal of Jilin University(Information Science Edition), 2023, 41(6): 998−1006.
[3] 倪建云,杜合磊,谷海青,等. 改进人工势场法的移动机器人路径规划研究[J]. 重庆理工大学学报(自然科学),2023,37(11):247−256. NI Jianyun, DU Helei, GU Haiqing, et al. Improved artificial potential field method for mobile robots path planning study[J]. Journal of Chongqing University of Technology(Nature Science), 2023, 37(11): 247−256.
[4] 韩金利. 基于改进RRT算法的路径规划研究[J]. 机械工程与自动化,2023,37(11):31−33. HAN Jinli. Research on path planning based on improved RRT algorithm[J]. Mechanical Engineering and Automation, 2023, 37(11): 31−33.
[5] 张纳川,王亚飞,章冀辰,等. 面向铲装作业场景的自动驾驶矿车路径规划方法研究[J]. 汽车工程学报,2023,13(1):22−29. ZHANG Nachuan, WANG Yafei, ZHANG Jichen, et al. Path planning method for autonomous driving mining vehicles in shovel loading operation scenarios[J]. Chinese Journal of Automotive Engineering, 2023, 13(1): 22−29.
[6] 刘威,储春华,肖明伟. 一种基于时间和路径双重优化的改进A*算法[J]. 制造业自动化,2023,45(12):173−177. LIU Wei, CHU Chunhua, XIAO Mingwei. An improved A*algorithm based on dual optimization of time and path[J]. Manufacturing Automation, 2023, 45(12): 173−177.
[7] 刘辉,肖克,王京擘. 基于改进蚁群算法的无人矿车路径规划研究[J]. 制造业自动化,2021,43(4):108−112. LIU Hui, XIAO Ke, WANG Jingbo. Research on path planning of driverless mining cars based on improved ant colony algorithm[J]. Manufacturing Automation, 2021, 43(4): 108−112.
[8] 宁竞,龙妍. 改进蚁群算法的煤矿巡检机器人路径规划[J]. 煤炭技术,2023,42(6):235−237. NING Jing, LONG Yan. Path planning of coal mine patrol robot based on improved ACO algorithm[J]. Coal Technology, 2023, 42(6): 235−237.
[9] 胡小建,杨智. 基于混合遗传算法的多拣货小车路径规划研究[J]. 合肥工业大学(自然科学版),2022,45(12):1715−1722. HU Xiaojian, YANG Zhi. Research on path planning of multi picking car based on hybrid genetic algorithm[J]. Journal of Hefei University of Technology(Natural Science), 2022, 45(12): 1715−1722.
[10] 王龙宝,栾茵琪,徐亮,等. 基于动态簇粒子群优化的无人机集群路径规划方法[J]. 计算机应用,2023,43(12):3816−3823. WANG Longbao, LUAN Yinqi, XU Liang, et al. Route planning method of UAV swarm based on dynamic cluster particle swarm optimization[J]. Journal of Computer Applications, 2023, 43(12): 3816−3823.
[11] 吴东领,魏群,刘心军. 面向煤矿救援机器人路径规划的重回放机制DQN算法[J]. 煤炭技术,2023,42(5):237−240. WU Dongling, WEI Qun, LIU Xinjun. Replay mechanism DQN algorithm for path planning of coal mine rescue robots[J]. Coal Technology, 2023, 42(5): 237−240.
-
期刊类型引用(1)
1. 朱翠,罗宇豪,王占刚,戴娟. 新型蚁群算法规划核电厂巡检机器人路径. 核电子学与探测技术. 2025(01): 107-115 .  百度学术
百度学术
其他类型引用(0)
 下载:
下载:
计量
- 文章访问数: 27
- HTML全文浏览量: 2
- PDF下载量: 6
- 被引次数: 1
