
Improvement of YOLOv7 model for intelligent recognition of mining surface cracks
-
摘要:
矿山开采引起的地表裂缝对煤矿安全生产造成严重影响,利用无人机影像识别采煤沉陷区裂缝发育特征具有实用价值。提出了一种改进的YOLOv7采动裂缝智能化识别模型,通过在模型主干网络中添加GAM全局注意力机制,减少图像卷积过程中特征信息的丢失;同时,引入深度可分离卷积代替主干网络中的普通卷积,使得图像特征图尺寸减半,而卷积过程中并不会造成特征缺失;进一步采用GIOU_Loss对网络边界框损失函数进行改进,提升了模型的小目标识别能力;使用LabelImg图像标注软件制作包含2143张$ 5\;472\times 3\;648 $ pixels的采动裂缝识别训练数据集,对沉陷区无人机影像进行初处理构建DOM后,使用$ 640\times 640 $的滑动窗口裁剪DOM,对裁剪后的DOM进行特征识别。结果表明:改进后的YOLOv7模型对于密集、细小、植被覆盖3类裂缝图像的识别效果和漏检情况得到明显改善,平均准确度(mAP)达到0.84。
Abstract:The surface cracks caused by mining have a significant impact on the safety production of coal mines. Utilizing unmanned aerial vehicle (UAV) image recognition to identify the development characteristics of cracks in coal mining subsidence areas holds practical value. In this paper, an improved YOLOv7 model for intelligent recognition of mining-induced cracks is proposed. It incorporates the GAM global attention mechanism into the backbone network of the model to reduce the loss of feature information during the image convolution process. Additionally, depth-wise separable convolutions are introduced to replace the ordinary convolutions in the backbone network, which reduces the size of the image feature map without causing feature loss during the convolution process. Furthermore, GIOU_Loss is further used to improve the network boundary frame loss function, which improves the small target identification ability of the model. For the experiments, a training dataset for mining-induced crack recognition was created using the LabelImg image annotation software, containing 2 143 images with a resolution of 5 472×3 648 pixels. After initial preprocessing of the UAV images in the subsidence area to construct a digital orthophoto model (DOM), the DOM was further cropped using a sliding window of size 640×640 for feature recognition. The experimental results demonstrate that the improved YOLOv7 model exhibits significant improvements in the recognition performance and missed detections of dense, small-sized, and vegetation-covered crack images. The average precision (mAP) reaches 0.84.
-
Keywords:
- UAV imagery /
- mining-induced cracks /
- feature extraction /
- YOLOv7 /
- global attention mechanism
-
煤炭资源大规模、高强度开采引发严重的采动损害,对矿区地表生态环境造成严重破坏[1]。地下煤层大面积采空后,对上覆岩层和地表不可避免地造成破坏[2]。采动损害与采矿地质条件、土地类型、土壤特性等因素相关[3-4],采煤塌陷区的地裂缝是采动损害的重要类型,对矿山安全生产和居民生活造成严重影响[5-8]。因此,快速、准确识别地表裂缝信息对于避免地质灾害发生,减少经济损失和保护生态环境具有重要意义[9]。
近年来,无人机低空遥感技术被广泛应用于矿山地表损害监测和智能化识别[10]。一些学者利用无人机影像对裂缝进行识别,获得了良好的效果。汤伏全等[11]应用最大似然算法(MLM)对采动地表裂缝进行提取;韦博文等[12]基于无人机影像提出了一种改进的MF-FDOG算法,在提取黄土高原地区的细小裂缝方面效果较好,但不适用于非线性分布的裂缝提取;郝明等[13]通过改进主动轮廓模型提取高寒地区露天矿地裂缝,结果优于传统的Canny边缘检测算法、MLM、支持向量机(SVM)等算法,但算法的普适性有待进一步研究。随着人工智能技术的快速发展,利用深度学习模型如YOLOv5和U-Net3+等识别和提取地表裂缝已取得许多应用成果[13-14]。然而,利用深度学习模型开展矿山采动地表裂缝的智能化识别和提取,需要进行大量的样本训练才能实现,目前研究尚处于初步探索阶段。
为此,以目前广泛应用的深度学习模型YOLOv7为基础,针对该模型应用于矿山采动地表裂缝智能识别中存在的小目标提取精度不足等问题,开展模型算法改进;以黄土高原大佛寺煤矿综采工作面地表塌陷区为研究场地,利用无人机影像获取采动裂缝信息,构建裂缝样本训练集,使用改进的YOLOv7模型进行裂缝识别。
1. 矿区地表无人机影像采集与处理
1.1 研究区概况
研究区位于彬长矿区大佛寺煤矿综放工作面开采沉陷区,整体以宽缓的黄土台塬为主,中部、东北部为沟壑地貌边缘。地表高程范围为+907.6~+1118.8 m。平均采动厚度6.7 m,平均煤层倾角5°,平均开采深度405 m,开采宽度300 m,推进长度800 m。外业航飞范围为1000 m×700 m的矩形区域。
采用大疆精灵4pro进行低空无人机航测数据采集。机型号为FC6310S,镜头焦距为8.8 mm,像素大小为2.41 μm。由于航测区域地形较为平缓,且航测区域分布有高压塔等电力设施,考虑到飞行安全,设置相对航高为100 m,航向重叠度为80%,旁向重叠度为70%。该航拍条件下对应的地面分辨率为30 mm。在工作面推采至730 m于2023年3月7日对研究区域进行航飞。在航飞区域大致均匀地布设6个像控点,另布设23个检查点。
1.2 基于影像的DOM构建和影像数据误差
开采工作面及地貌示意图如图1所示。
由于无人机影像存在畸变,在提取裂缝的过程中存在近大远小等问题导致不能准确反映裂缝的真实位置信息,构建正射影像可以消除地面起伏和无人机姿态改变等因素带来的位移,有效解决的影像畸变等问题。故研究在影像初处理阶段利用smart3D软件进行无人机影像处理,包括相机检校、影像校正、配准空中三角测量解算生成密集点云数据后,将密集点云数据导入Context Capture三维建模软件生成正射影像模型(DOM)。
为了分析无人机影像数据的误差,通过生成的数字表面模型(DSM)中的检查点的和像控点的平面坐标及高程值,将其与实测数据进行对比,计算影像数据平面坐标和高程的中误差。
影像中检查点与像控点的中误差统计为:①控制点平面误差0.6 mm,高程误差0.9 mm;②检查点平面误差34 mm,高程误差49 mm。
2. YOLOv7裂缝识别模型实现
2.1 YOLOv7裂缝识别模型
YOLOv7是一种目标识别模型,YOLOv7通过使用更快的网络结构,以及更高效的卷积操作和数据并行技术来提高识别速度。同时,增加了对多个分辨率图像的输入支持,并在每个分辨率上生成独立的结果,从而提高识别精度。
研究采用Python3.10编程语言及Pycharm平台搭建YOLOv7裂缝识别定位模型,并通过增加模型深度及通道特征提升模型对图像特征的识别能力。同时采用GIOU_Loss对网络边界框损失函数进行改进,进一步提升模型的识别精度。
YOLOv7网络架构如图2所示。
在网络架构中,输入端主要通过Mosaic数据增强、自适应锚框计算、自适应图片缩放等方式丰富数据集,以及减少GPU的运算负载,提高效率。在VOLOv7中,主要使用640$ \times $640 pixels或1280$ \times $1280 pixels这样相对较大的图片上进行训练和测试。在主干网络中,首先通过4层卷积模块,将输入的图像通过4次上采样的操作进行特征融合,结合不同尺度的特征信息从而加强特征提取,后通过4层特征提取模块输出3种不同尺度的特征图像(C3,C4,C5)。在预测阶段,将主干网络最后输出的C5最大池化和下采样,并从上到下与C4,C3进行融合,得到3种特征图(P3, P4, P5),再按照从下至上的顺序与P4、P5做融合,之后进行训练和推理,最后使用$ 1\times 1 $的卷积进行预测。在预测过程中根据特征信息标记边界框,以损失值(GIOU_Loss)作为边界框的损失函数,损失值计算公式如下:
$$ \mathrm{G}\mathrm{I}\mathrm{O}\mathrm{U}\_\mathrm{L}\mathrm{o}\mathrm{s}\mathrm{s}=\mathrm{I}\mathrm{O}\mathrm{U}-|\left({S}-{E}\right)/{S} $$ (1) 式中:IOU为预测框和实际框的交集与并集面积之比;S为指预测框和实际框之间的最小外接矩形的面积[15];E为指连外接矩形中除了预测框和实际框之外的其他部分的面积。
识别框示意图如图3所示。由图3可以看出:随着预测框和实际框的重合程度的增加,S会变得更小,从而使GIOU_Loss也会变得更小。经过损失计算确定目标类的概率以及边框的最终位置。然后,使用非极大抑制(NMS)来消除多余的识别框,从而找到最优的锚定框[16]。
3. YOLOv7目标识别模型的改进
3.1 MPConv改进模块
在YOLOv7模型网络中,特征提取(MPConv)模块分为2个分支。在上分支中,特征图在最大池化层后进行$ 1\times 1 $(卷积核大小为1,卷积核每次移动的距离为1pixel)的卷积运算。通过选取局部最大值对图像的边缘和纹理信息进行学习。在下分支中,特征图通过$ 1\times 1 $的卷积运算后又会进行1个$ 3\times 2 $的卷积运算。通过2个卷积级联,提取得到了图像的更多细节信息。最后将2个分支的特征进行合并,使得在特征提取模块中为模型带来了更好的信息融合效果。当选择卷积核为3、步长为2的卷积时,卷积过程会造成一些细粒度的丢失,从而使得网络产生低效率的特征表示学习。步长为2时的卷积过程如图4所示。
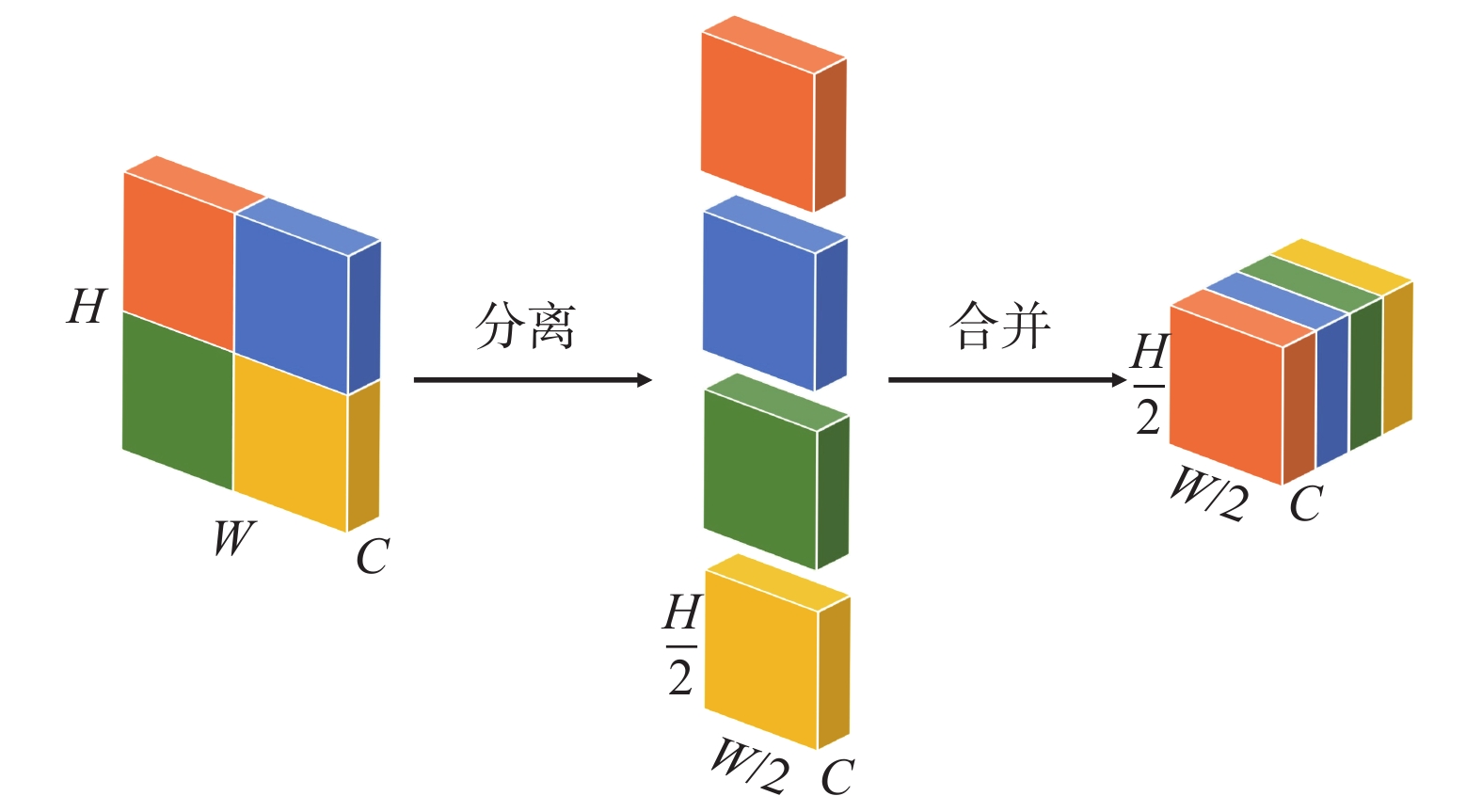
为了防止这种因步长为2而导致小目标网络特征缺失的情况发生,需要分割和组合运算,分离合并操作示意图如图5所示,图中C为特征图像的特征维度。
由图5可知:对1张包含W(宽)×H(高)像素的图片,将其分割成4个(W/2)×(H/2)个子图,再把4个子图按特征维度进行合并。分割、合并后将特征进行$ 1\times 1 $的卷积运算即可获得(W/2)×(H/2)×1尺寸特征图。
MPConv框架如图6所示。改进后MPConv模块的右分支与改进前一致,同样实现了特征图尺寸减半的目的,但操作过程中不会造成细小特征的缺失。
将主干网络结构中的MPConv模块替换为改进后的MPConv模块后,在特征提取的过程中可以提取到更多有效的信息。
3.2 GAM注意力模块
GAM是一种注意力机制[17],能够在减少信息生成的情况下放大全局维度交互特征的机制,稳定地提升模型识别的性能,包括目标的通道特征和空间特征。在本文中,定义输入的特征映射为$ {F}_{1}\in {R}^{C H W} $,则中间状态变量F2和最终输出F3的表达式如下:
$$ {F}_{2}={M}_{{\mathrm{c}}}\left({F}_{1}\right)\otimes {F}_{1} $$ (2) $$ {F}_{3}={M}_{{\mathrm{S}}}\left({F}_{2}\right)\otimes {F}_{2} $$ (3) 式中:$ {M}_{{\mathrm{c}}} $、$ {M}_{{\mathrm{s}}} $分别为通道和空间注意力图;$ \otimes $为元素方式的乘法计算。
GAM模块框架如图7所示。
由图7可知:输入特征F1经过通道子注意力单元最终输出为1个特征值F3,通道注意子模块使用3D排列来保留跨三维的信息,通过双层MLP(多层感知器)来放大跨维度通道空间依赖,而在空间注意子模块中,使用了2个卷积层进行空间信息融合,充分聚焦空间信息[18]。
4. 采动裂缝识别模型训练
训练裂缝识别模型前首先需要建立裂缝识别数据集,同时对数据集图像进行增强。将数据集按照4∶1划分为训练集和测试集后输入网络进行训练。模型通过卷及运算学习裂缝数据集特征,利用反向传播和梯度下降方法不断优化模型参数,达到裂缝识别与定位的目的。
1)裂缝识别数据集制作。使用无人机在距离地面10~110 m的高度对试验区域进行多高度拍摄,共获取到2130张地表裂缝影像,将影像像按照4∶1划分训练集和测试集,即训练集包含1704张图像,测试集包含426张图像,并使用LabelImg进行人工标注。为提高模型泛化能力,增强鲁棒性,利用增加高斯噪声,松泊噪声及调整图像对比度、明暗度等数据增强手段,对数据集样本数量进行扩充。
2)YOLOv7裂缝识别模型训练。裂缝识别定位模型训练在COCO数据集预训练完成的YOLOv7模型作为初始模型,设置训练批量大小为32张,输入图像大小为640$ \times $640 pixels,最大训练轮次为900次,同时为了防止模型出现过拟合现象,采用网络输出的最佳训练权重文件来构建裂缝识别定位模型。设置YOLOV7网络结构初始学习率为0.01,参数优化器为随机梯度下降,权重衰减系数为0.0005,动量常数取0.937,模型预热时间为3轮。
5. 裂缝识别模型测试与评估
测试模型为影像生成的DOM,由于DOM图像尺寸太大,导致识别速度大为降低,而且受到图像压缩的影像,导致识别精度不高。为了使模型能够更精确的识别地表裂缝,提出一种方法来裁剪DOM,方法流程是使用固定尺寸的滑动窗口在影像中循环移动裁剪DOM,再使用模型对裁剪后的图像进行识别。
主要选取准确率(P)-召回率(R)曲线、平均准确率(AP)和平均准确率均值(mAP)3个指标,计算公式如下:
$$ P=\frac{{\mathrm{{T}{TP}}}}{{\mathrm{{T}{TP}}}+{\mathrm{{F}{FP}}}}\times 100\mathrm{\%} $$ $$ R=\frac{{{\mathrm{T}}}{{\mathrm{TP}}}}{{{\mathrm{T}}}{{\mathrm{TP}}}+{{\mathrm{F}}}{{\mathrm{FN}}}}\times 100 $$ (4) $$ {{\mathrm{AP}}}={\int }_{0}^{1}P\left(R\right){\mathrm{d}}R $$ 式中:TTP为正确预测;FFP为错误预测,包括把不是裂缝的目标识别为裂缝和漏检2种情况;FFN为误把裂缝目标识别为其他类别的情况。
在P-R曲线中,P-R曲线与坐标轴围成的面积等于AP值大小。对所有类别的AP值取平均值就可以得到mAP,一般地,使用平均准确率(mAP)来对整个目标识别网络模型的识别性能进行评价。
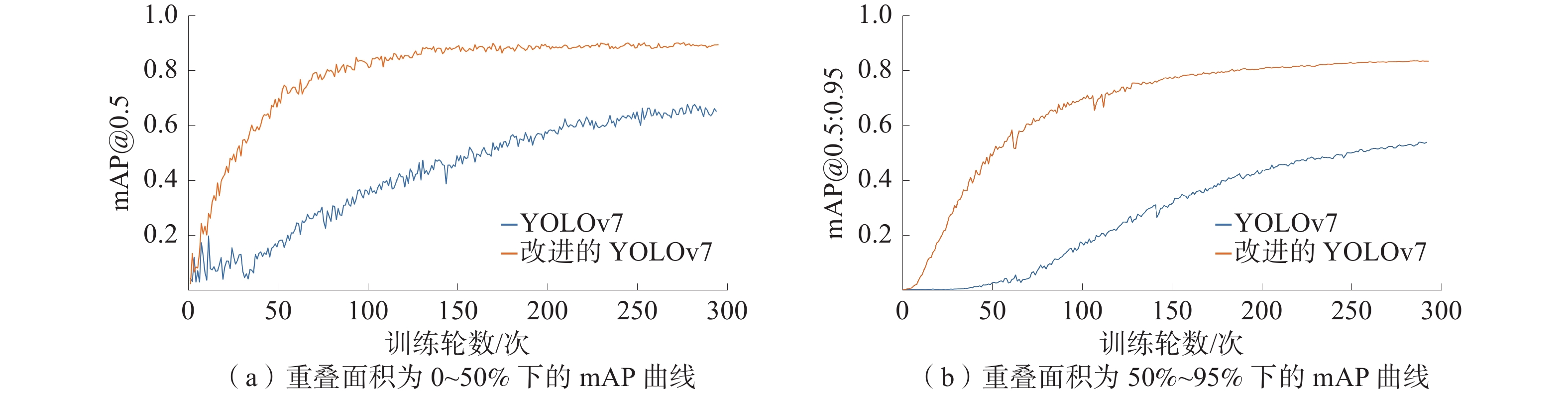
改进前后的网络模型对于裂缝的识别得出mAP曲线对比图如图8所示。图中:mAP@0.5为改进后的模型在预测框和实际框的交集面积占实际框面积0~50%情况下的识别准确率;mAP@0.5∶0.95为改进后的模型在预测框和实际框的交集面积占实际框面积50%~95%情况下的识别准确率。
![]() 图 8 改进后的YOLOv7模型mAP曲线对比Figure 8. Comparison of mAP curves of the improved YOLOv7 model
图 8 改进后的YOLOv7模型mAP曲线对比Figure 8. Comparison of mAP curves of the improved YOLOv7 model由图8可知:改进后的YOLOv7裂缝识别模型的mAP@0.5和mAP@0.5∶0.95 2个性能指标均高于原模型。改进后的YOLOv7模型在小裂缝的识别中取得了较好的性能。
针对矿区实际情况,选取裂缝分布密集、包含细小裂缝、有植被遮挡裂缝3种图像用于训练效果对比。基础YOLOv7模型与改进后的YOLOv7模型识别效果如图9~图11所示。
![]() 图 9 裂缝分布密集的图像识别结果对比Figure 9. Comparison of recognition results for images with dense cracks distribution
图 9 裂缝分布密集的图像识别结果对比Figure 9. Comparison of recognition results for images with dense cracks distribution![]() 图 10 包含细小裂缝的图像识别结果对比Figure 10. Comparison of recognition results of images containing small cracks
图 10 包含细小裂缝的图像识别结果对比Figure 10. Comparison of recognition results of images containing small cracks![]() 图 11 有植被遮挡裂缝的图像识别结果对比Figure 11. Comparison of recognition results for images with cracks occluded by vegetation
图 11 有植被遮挡裂缝的图像识别结果对比Figure 11. Comparison of recognition results for images with cracks occluded by vegetation在图9(a)中,使用原始yolov7模型对裂缝进行识别,由于在模型训练的过程中没有加入针对细小目标的特征的注意力机制,导致模型识别出的裂缝置信度较低;而在显示识别框的过程中会自动过滤掉置信度低于40%的裂缝,所以在图中并没有显示裂缝。在图9(b)中,改进后的模型在识别过程中,将大的裂缝分成许多细小的裂缝,很好的反映了裂缝的分布,方向等信息。对于有部分植被覆盖的裂缝区域(图11),改进后的模型对植被覆盖的裂缝的识别精度更高。
在保证配置环境及、训练数据集和初始训练参数一致的情况下,将改进后的YOLOv7裂缝识别模型与其他网络模型进行相同实验来验证改进模型的有效性,YOLOv5模型、PeleeNet_YOLOv3模型、YOLOv7模型、本文算法模型的mAP@0.5分别为0.66、0.85、0.66、0.92,相应的mAP@0.5:0.95分别为0.53、0.77、0.54、0.84。可以看出:改进后的YOLOv7网络模型在输入相同尺寸图片的情况下,mAP值超过了其他网络模型,更适合对采空区地表裂缝的识别场景。
批量识别矿区的DOM后,得到大量的识别框和识别框的长W(像素)、宽H(像素)和左上顶点的坐标P(x,y)。通过识别框的顶点坐标计算每个识别框的中心坐标P0并记录。计算公式如下:
$$ P_0=P\left(x+\frac{W}{2},y+\frac{H}{2}\right) $$ (5) 由于同1条裂缝有多个相互有重叠的识别框。且大型裂缝之间距离较远。经过不但调整距离阈值,将1个识别框中心点附近2 m的识别框视为同1条裂缝,将同1条裂缝的识别框中心点通过最小二乘法拟合为1条裂缝曲线。从而获取整个采空区附近的裂缝分布图,并通过DOM的坐标确定裂缝的位置。提取的采动地表裂缝示意图如图12所示。
6. 结 语
1)改进的YOLOv7模型通过修改模型的初始锚框尺寸,使锚框尺寸更适应裂缝的尺寸特征,达到了最优训练效果。
2)在图像特征卷积过程中,使用专门的算法对特征图像分块再叠放,减少了原始图像中细小特征的损失。
3)在模型训练过程中加入通道注意力机制和空间注意力机制,使改进的模型更加注意采动地表裂缝的颜色、分布等特征,取得了很好的效果。结果表明:改进后的YOLOv7模型对细小裂缝的识别效果显著优于PeleeNet_YOLOV3、YOLOV5等现有模型。
-
![]()
图 8 改进后的YOLOv7模型mAP曲线对比
Figure 8. Comparison of mAP curves of the improved YOLOv7 model
![]()
图 9 裂缝分布密集的图像识别结果对比
Figure 9. Comparison of recognition results for images with dense cracks distribution
![]()
图 10 包含细小裂缝的图像识别结果对比
Figure 10. Comparison of recognition results of images containing small cracks
![]()
图 11 有植被遮挡裂缝的图像识别结果对比
Figure 11. Comparison of recognition results for images with cracks occluded by vegetation
-
[1] 胡炳南,郭文砚. 采煤沉陷区损害防治对策与技术发展方向[J]. 煤炭科学技术,2022,50(5):21−29. HU Bingnan, GUO Wenyan. Counter measures and technical development direction of damage prevention in coal mining subsidence area[J]. Coal Science and Technology, 2022, 50(5): 21−29.
[2] 陈超,胡振琪. 我国采动地裂缝形成机理研究进展[J]. 煤炭学报,2018,43(3):810−823. CHEN Chao, HU Zhenqi. Research advances in formation mechanism of ground crack due to coal mining subsidence in China[J]. Journal of China Coal Society, 2018, 43(3): 810−823.
[3] 张平. 黄土沟壑区采动地表沉陷破坏规律研究[D]. 西安:西安科技大学,2010. [4] 苗彦平,谢晓深,陈小绳,等. 浅埋煤层开采地表裂缝发育规律及机理研究[J]. 煤矿安全,2022,53(4):209−215. MIAO Yanping, XIE Xiaoshen, CHEN Xiaosheng, et al. Development law and mechanism of surface cracks caused by shallow coal seam mining[J]. Safety in Coal Mines, 2022, 53(4): 209−215.
[5] 杨泽元,范立民,许登科,等. 陕北风沙滩地区采煤塌陷裂缝对包气带水分运移的影响:模型建立[J]. 煤炭学报,2017,42(1):155−161. YANG Zeyuan, FAN Limin, XU Dengke, et al. Influence of fissures due to coal mining on moisture transportation in the vadose zone in the blown-sand region of the Northern Shaanxi Province: Model establishment[J]. Journal of China Coal Society, 2017, 42(1): 155−161.
[6] 杨伟峰,隋旺华,吉育兵,等. 薄基岩采动裂缝水砂流运移过程的模拟试验[J]. 煤炭学报,2012,37(1):141−146. YANG Weifeng, SUI Wanghua, JI Yubing, et al. Experimental research on the movement process of mixed water and sand flow across overburden fissures in thin bedrock induced by mining[J]. Journal of China Coal Society, 2012, 37(1): 141−146.
[7] 侯恩科,张杰,谢晓深,等. 无人机遥感与卫星遥感在采煤地表裂缝识别中的对比[J]. 地质通报,2019,38(2):443−448. HOU Enke, ZHANG Jie, XIE Xiaoshen, et al. Contrast application of unmanned aerial vehicle remote sensing and satellite remote sensing technology relating to ground surface cracks recognition in coal mining area[J]. Geological Bulletin of China, 2019, 38(2): 443−448.
[8] 吴群英,冯泽伟,胡振琪,等. 生态脆弱矿区地表裂缝动态变化对土壤含水量的影响[J]. 煤炭科学技术,2020,48(4):148−155. WU Qunying, FENG Zewei, HU Zhenqi, et al. Influence of dynamic variation of ground cracks on soil water content in ecological-fragile coal mining areas[J]. Coal Science and Technology, 2020, 48(4): 148−155.
[9] 郭晨,许强,董秀军,等. 无人机在重大地质灾害应急调查中的应用[J]. 测绘通报,2020(10):6−11. GUO Chen, XU Qiang, DONG Xiujun, et al. Application of UAV photogrammetry technology in the emergency rescue of catastrophic geohazards[J]. Bulletin of Surveying and Mapping, 2020(10): 6−11.
[10] 胡晓,李新举. 基于无人机的高潜水位煤矿区沉陷耕地提取方法比较[J]. 煤炭学报,2019,44(11):3547−3555. HU Xiao, LI Xinju. Comparison of subsided cultivated land extraction methods in high-groundwater-level coal mines based on unmanned aerial vehicle[J]. Journal of China Coal Society, 2019, 44(11): 3547−3555.
[11] 汤伏全,李林宽,李小涛,等. 基于无人机影像的采动地表裂缝特征研究[J]. 煤炭科学技术,2020,48(10):130−136. TANG Fuquan, LI Linkuan, LI Xiaotao, et al. Research on characteristics of mining-induced surface cracks based on UAV images[J]. Coal Science and Technology, 2020, 48(10): 130−136.
[12] 韦博文,刘国祥,汪致恒. 基于改进的MF-FDOG算法和无人机影像提取黄土地区地裂缝[J]. 测绘,2018,41(2):51−56. WEI Bowen, LIU Guoxiang, WANG Zhiheng. Extracting ground fissures in loess landform area using modified F-FDOG algorithm and UAV images[J]. Surveying and Mapping, 2018, 41(2): 51−56.
[13] 郝明,林惠晶,高彦彦. 基于改进主动轮廓模型的无人机影像矿区地裂缝提取[J]. 地球信息科学学报,2022,24(12):2448−2457. HAO Ming, LIN Huijing, GAO Yanyan. Ground fissure extraction method based on improved active contour model for UAV images in mining areas[J]. Journal of Geo-information Science, 2022, 24(12): 2448−2457.
[14] 余加勇,刘宝麟,尹东,等. 基于YOLOv5和U-Net3+的桥梁裂缝智能识别与测量[J]. 湖南大学学报(自然科学版),2023,50(5):65−73. YU Jiayong, LIU Baolin, YIN Dong, et al. Intelligent identification and measurement of bridge cracks based on YOLOv5 and U-Net3+[J]. Journal of Hunan University(Natural Sciences), 2023, 50(5): 65−73.
[15] ZHOU D F, FANG J, SONG X B, et al. IoU loss for 2D/3D object detection[C]//Proceedings of 2019 International Conference on 3D Vision. Washington D. C. , USA: IEEE Press, 2019: 85-94.
[16] ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[J]. Artificial Intelligence, 2020, 34(7): 12993−13000.
[17] NIU Z Y. A review on the attention mechanism of deep learning[J]. Neurocomputing, 2021, 452: 48−62. doi: 10.1016/j.neucom.2021.03.091
[18] 戚玲珑,高建瓴. 基于改进YOLOv7的小目标检测[J]. 计算机工程,2023,49(1):41−48. QI Linglong, GAO Jianling. Small object detection based on improved YOLOv7[J]. Computer Engineering, 2023, 49(1): 41−48.
-
期刊类型引用(1)
1. 范铭今,陈军涛,古海龙,唐道增,韩港,张树强,李光强. 西部矿区可注断层破碎带注浆加固特性试验研究. 煤矿安全. 2025(01): 155-163 .  本站查看
本站查看
其他类型引用(0)
 下载:
下载:










计量
- 文章访问数: 49
- HTML全文浏览量: 11
- PDF下载量: 20
- 被引次数: 1
